


统一SQL引擎



通过内存中执行查询和高效矢量化执行引擎,支持近实时的交互分析。

提供统一的查询范式,屏蔽底层细节,允许用户使用熟悉的 SQL 语言进行复杂的数据查询和分析。

将部署程序与数据引擎的具体版本解耦,实现产品程序的跨平台、跨引擎的灵活的迁移能力。

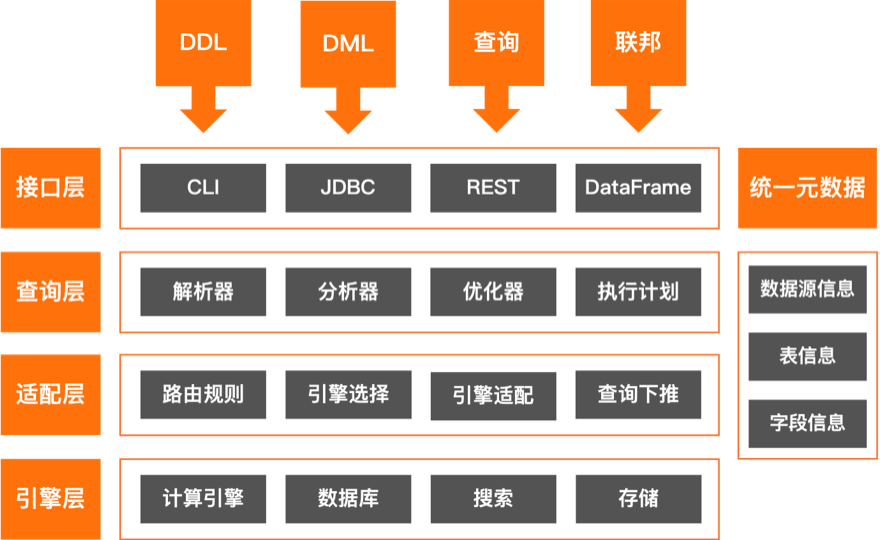
通过统一的SQL查询引擎,屏蔽底层异构数据源的复杂性,用户无需关心数据物理位置和存储格式,使用标准SQL语句访问关系型数据库、NoSQL数据库和数据湖在内的多种数据源,实现数据的跨源联合查询,极大地提升数据处理的灵活性和效率,满足企业在复杂数据生态系统中的多样化需求。

通过缓存、预计算和物化视图对查询进行加速,可以显著提高查询性能。物化视图将频繁执行的查询结果预先计算并存储,从而在需要时直接从物化视图中检索数据,避免了对基础表的访问,减少了I/O操作。并且允许用户将聚合、过滤、投影等操作下推至数据引擎,实现毫秒级响应。
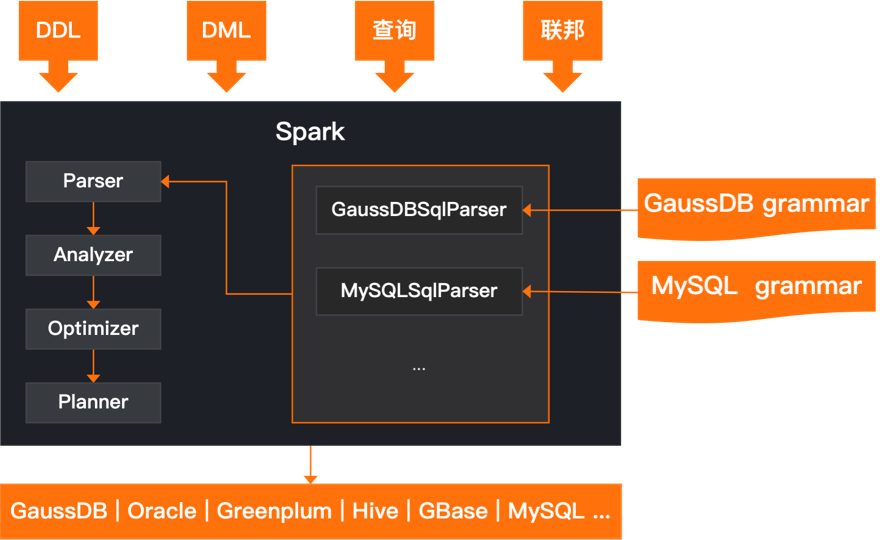
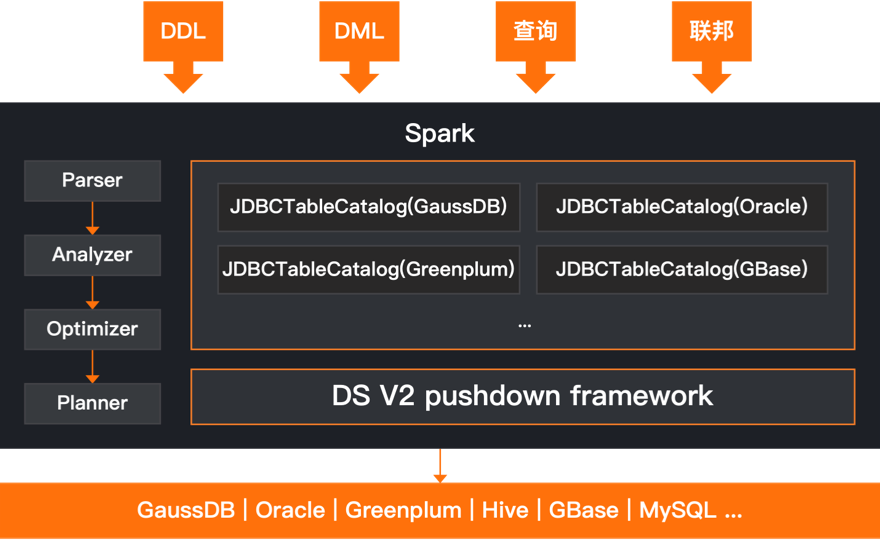
开发者可以根据需要灵活地扩展SQL构造和编译规则,生成适合于该特定数据库的效率较高的SQL语法,以便更好地满足实际场景。
通过统一的SQL查询引擎,屏蔽底层异构数据源的复杂性,用户无需关心数据物理位置和存储格式,使用标准SQL语句访问关系型数据库、NoSQL数据库和数据湖在内的多种数据源,实现数据的跨源联合查询,极大地提升数据处理的灵活性和效率,满足企业在复杂数据生态系统中的多样化需求。


业务痛点
数据分散存储在多个存储介质上,在进行数据产出时需要抽取合并不同介质的数据。
多种引擎存在语法差异,需要使用不同语法进行数据加工处理,对人员的技术门槛要求高。
业务价值
基于统一引擎技术和统一元数据系统,支持跨引擎的联邦查询引擎,在数据中心内为客户打通数据,将分散的数据以高性价比的方式实现融合计算和分析。减少不必要的数据传输和ETL,提升分析效率。
业务痛点
数据分散存储在多个存储介质上,在进行数据产出时需要抽取合并不同介质的数据。
多种引擎存在语法差异,需要使用不同语法进行数据加工处理,对人员的技术门槛要求高。
业务价值
基于统一引擎技术和统一元数据系统,支持跨引擎的联邦查询引擎,在数据中心内为客户打通数据,将分散的数据以高性价比的方式实现融合计算和分析。减少不必要的数据传输和ETL,提升分析效率。


数新智能公众号

数新智能科技号

数新智能抖音号

数新智能交流群
公众号
科技号
抖音号
交流群



