


算力平台


多机多卡的统一资源池管理,支持服务器通过端口授权方式,自动被平台识别并快速加入资源池,无需手动配置,在GPU需要维护或更换时,平台支持安全下架、平稳迁移。

对资源分配和任务协调的保障机制,在多任务环境中确保任务能够高效、有序地执行。在GPU未被充分利用时,支持切换至节能状态或进行重新分配,并实时监测资源使用情况,智能调度,避免过载。

通过算力共享机制,实现了GPU资源的公平分配和高效利用。平台集成了多种GPU加速插件,简化了用户的应用开发和部署流程,支持根据实际需求动态调整GPU资源的分配大小,进一步提升资源利用率。
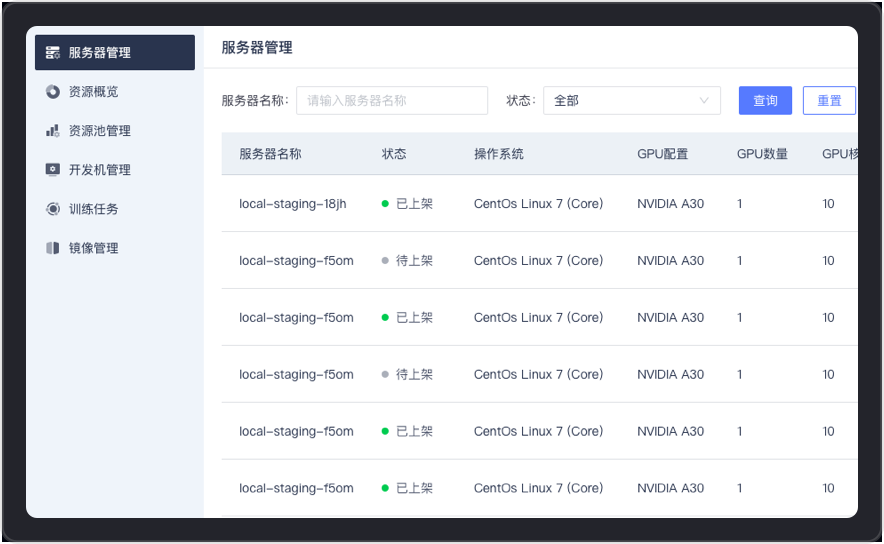
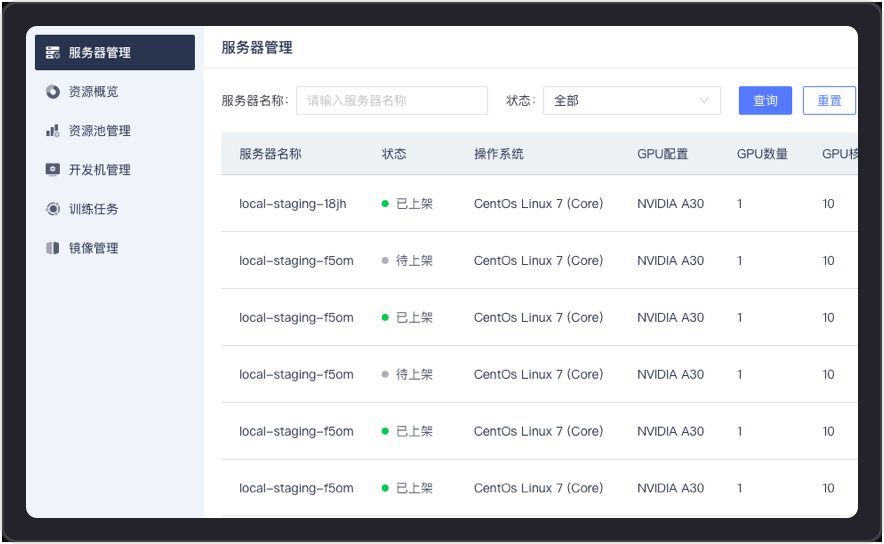
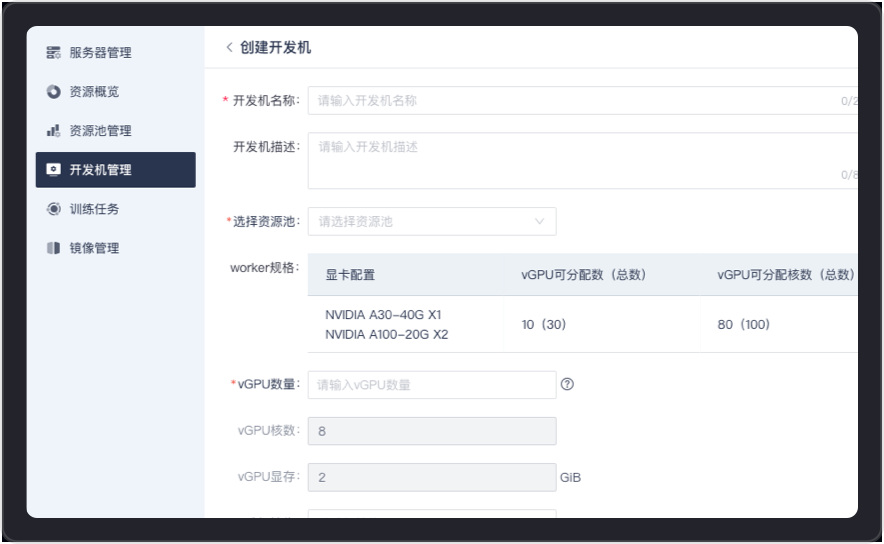
支持对服务器的创建、上架、下架、GPU虚拟化等全链路流程操作,通过端口授权可自动识别获取操作系统、GPU数量、GPU核数、GPU内存等完整信息,并进行服务器连通性测试和分析,确保资源的灵活配置和稳定可用。
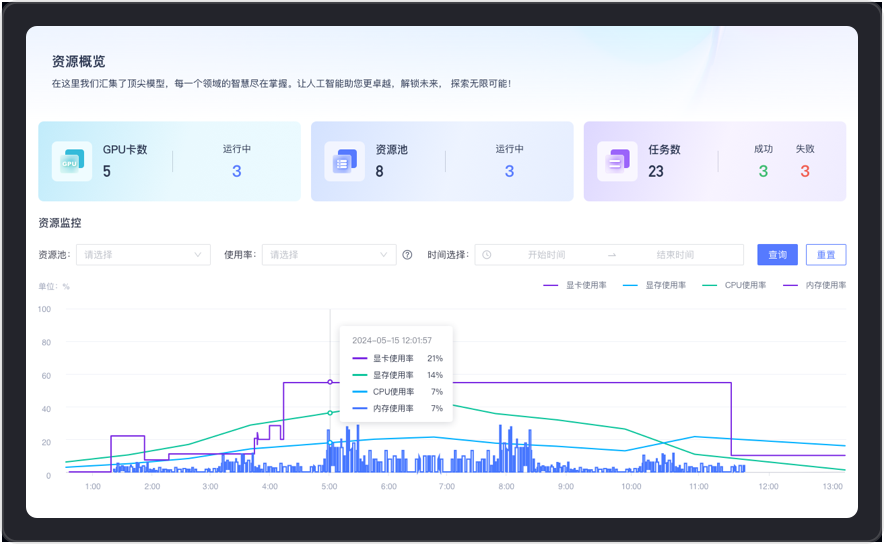
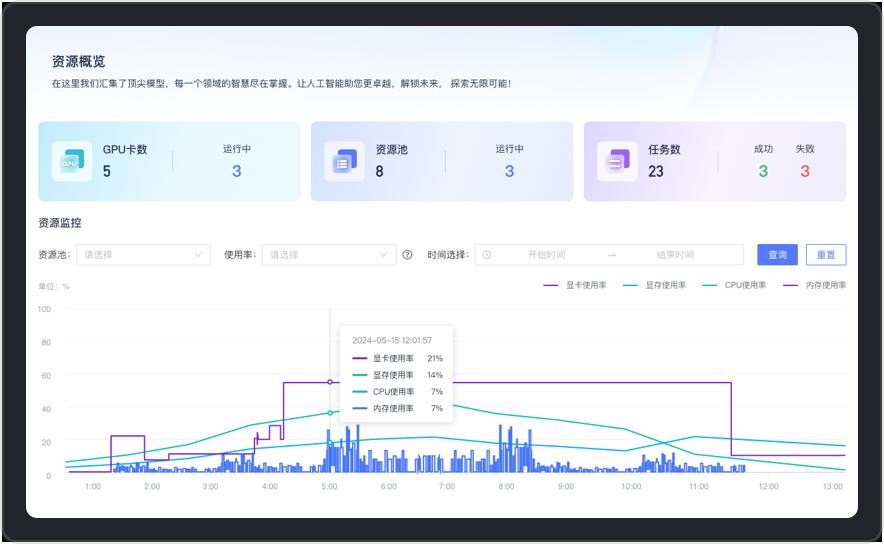
全面覆盖了GPU卡、资源池和任务级别的性能和状态监控,实时追踪监控资源池的使用情况,为系统健康和性能优化提供详尽的数据支持。支持GPU虚拟化、多机多卡并行训练,满足应用级别的算力管理。
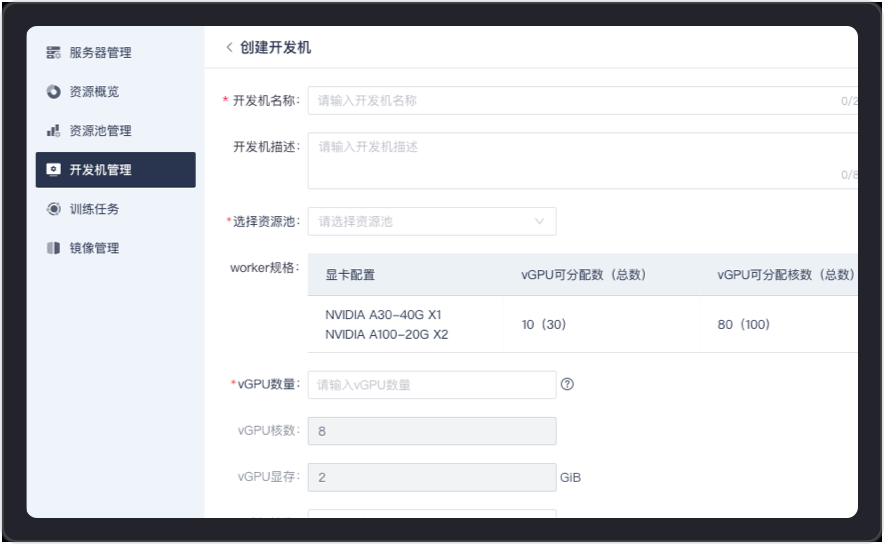
为用户提供了便捷的开发机创建和管理环境,可以根据实际需要自行通过资源池、vGPU数量、镜像以及系统盘大小等配置来创建开发机,同时为每个租户提供了高性能存储空间,实现租户安全隔离。
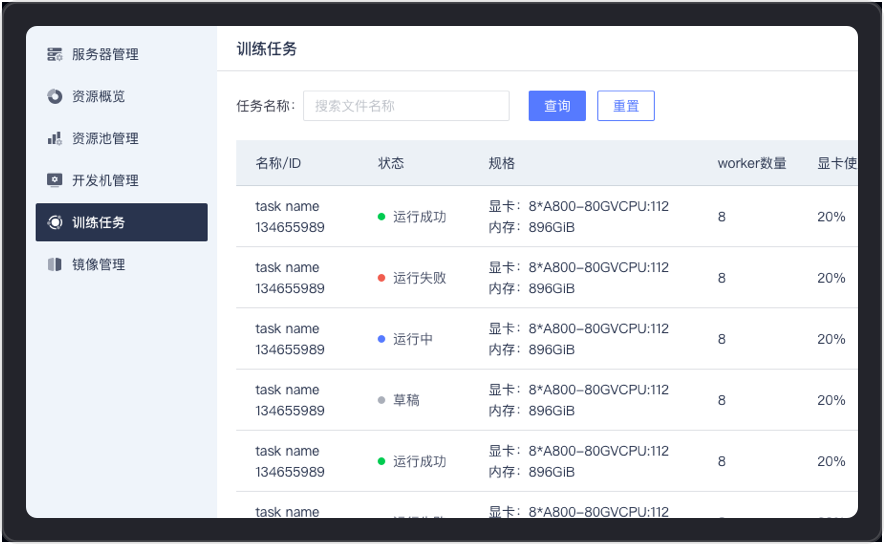
支持用户自定义训练参数和配置训练任务,提供任务异常检测、自动重启进程或重新调度能力。TensorBoard日志功能则为用户提供了可视化的训练过程监控和结果分析,进一步提高了训练效率和效果。
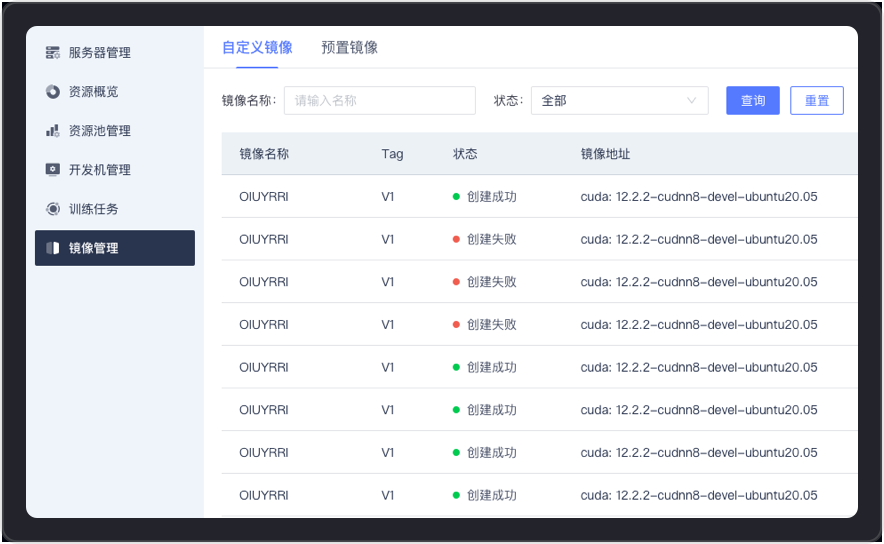
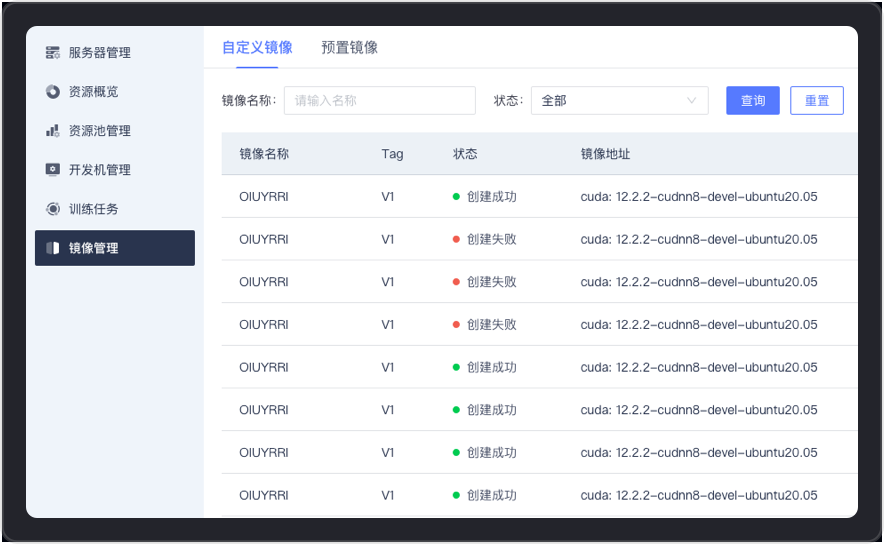
支持自定义镜像和预置镜像的管理和使用,用户可快速创建和部署镜像环境,服务应用于训练任务、开发机、Notebook建模实验室等,进一步满足了AI模型开发和训练过程中的多样化需求。
支持对服务器的创建、上架、下架、GPU虚拟化等全链路流程操作,通过端口授权可自动识别获取操作系统、GPU数量、GPU核数、GPU内存等完整信息,并进行服务器连通性测试和分析,确保资源的灵活配置和稳定可用。


业务痛点
企业内容数据、算法、服务各系统独立未实现有效整合,导致资源分散,管理和利用难度大。此外,算力中心不足,深度学习资源分配不均,无法满足模型训练和实时应用的需求。特征、模型和服务未统一,MLOps机器学习开发运维效率低,给企业带来巨大的挑战。
业务价值
整合提效:整合算力资源与机器学习平台,打通数据开发、特征管理及模型应用,提升数据效率与数据一致性。
资源调度:优化资源配置,提升特征平台和模型开发效率,支持大规模数据处理和复杂计算。
降本避险:提升数据处理与模型应用能力,降低人力、技术成本,减少数据泄露与业务中断风险,保障长期运营稳定可靠。
业务痛点
企业内容数据、算法、服务各系统独立未实现有效整合,导致资源分散,管理和利用难度大。此外,算力中心不足,深度学习资源分配不均,无法满足模型训练和实时应用的需求。特征、模型和服务未统一,MLOps机器学习开发运维效率低,给企业带来巨大的挑战。
业务价值
整合提效:整合算力资源与机器学习平台,打通数据开发、特征管理及模型应用,提升数据效率与数据一致性。
资源调度:优化资源配置,提升特征平台和模型开发效率,支持大规模数据处理和复杂计算。
降本避险:提升数据处理与模型应用能力,降低人力、技术成本,减少数据泄露与业务中断风险,保障长期运营稳定可靠。


数新智能公众号

数新智能科技号

数新智能抖音号

数新智能交流群
公众号
科技号
抖音号
交流群



