

 中文
中文Unified SQL Engine (CyberSQL)



Support near real-time interaction analysis through in-memory execution of queries and efficient vectorization execution engines.

Provides a unified query paradigm that masks the underlying details, allowing users to conduct complex data queries and analyses using the familiar SQL language.

The deployment program is decoupled from the specific version of the data engine to achieve cross-platform and cross-engine flexible migration capabilities of the product program.

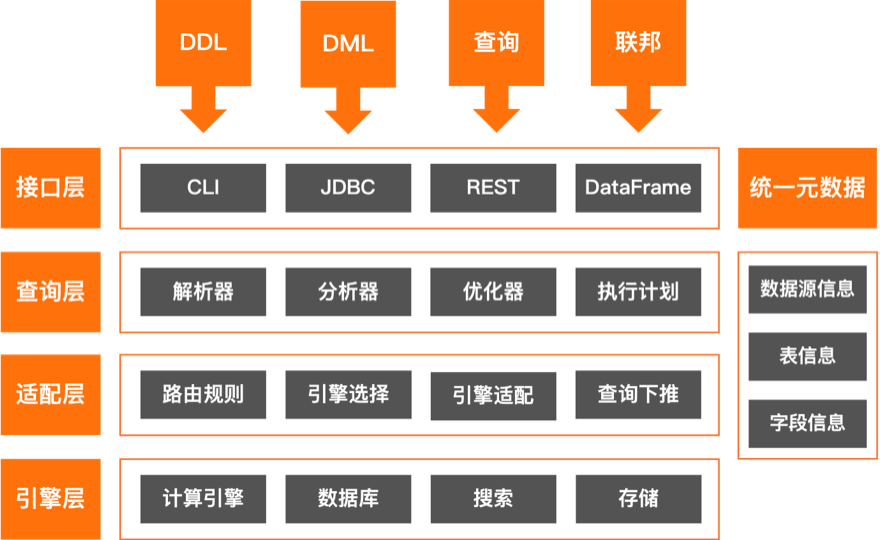
Through the unified SQL query engine, the complexity of the underlying heterogeneous data sources is shielded. Users do not need to care about the physical location and storage format of the data, and use standard SQL statements to access a variety of data sources, including relational databases, NoSQL databases, and data lakes, to achieve cross-source joint query of data, greatly improving the flexibility and efficiency of data processing, and meeting the diversified needs of enterprises in complex data ecosystems.

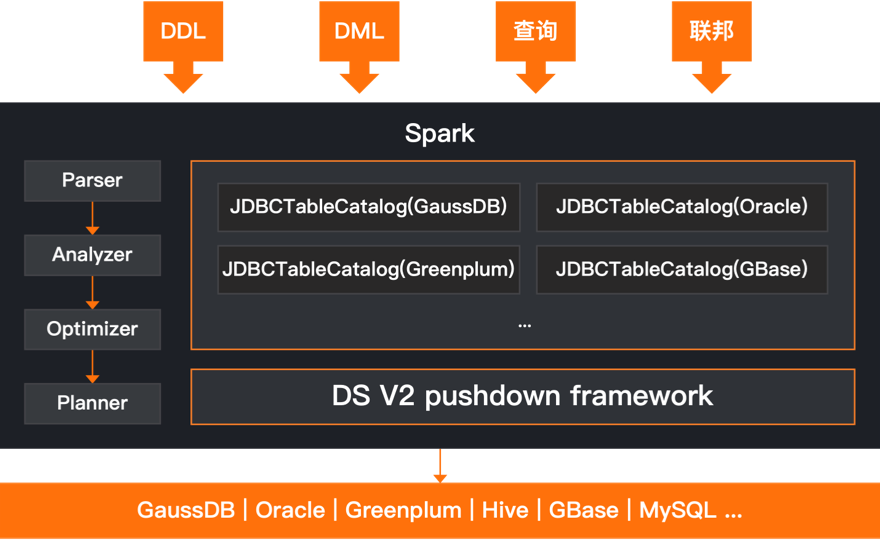
Accelerating queries through caching, precomputation, and materialized views can significantly improve query performance. The materialized view precomputes and stores frequently executed query results to retrieve data directly from the materialized view when needed, avoiding access to underlying tables and reducing I/O operations. And allows users to push aggregation, filtering, projection and other operations down to the data engine to achieve millisecond response.
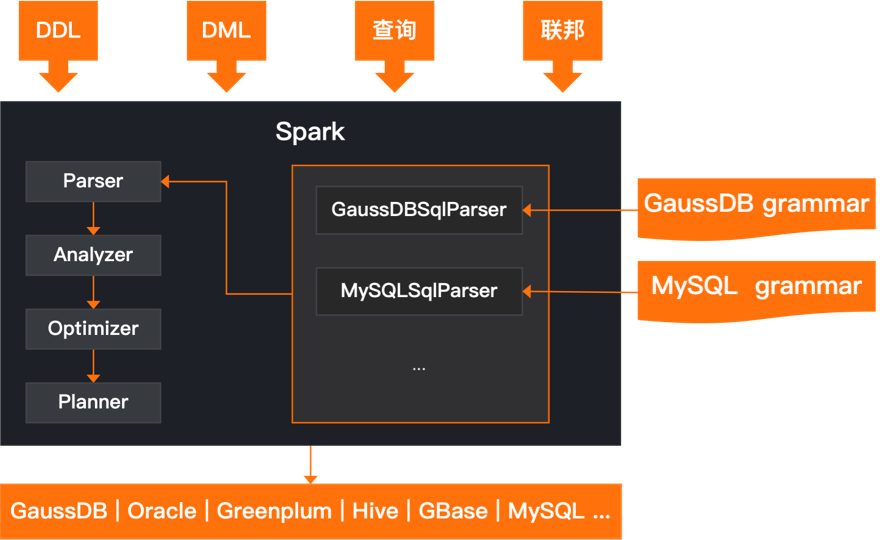
Developers can flexibly extend SQL construction and compilation rules as needed to generate more efficient SQL syntax for that particular database to better fit the actual scenario.
Through the unified SQL query engine, the complexity of the underlying heterogeneous data sources is shielded. Users do not need to care about the physical location and storage format of the data, and use standard SQL statements to access a variety of data sources, including relational databases, NoSQL databases, and data lakes, to achieve cross-source joint query of data, greatly improving the flexibility and efficiency of data processing, and meeting the diversified needs of enterprises in complex data ecosystems.


Business Pain Points
Data is scattered and stored on multiple storage media, and data from different media needs to be extracted and merged when data is produced.
There are grammatical differences in a variety of engines, which require different syntaxes for data processing, and the technical threshold for personnel is high.
Business Value
Based on unified engine technology and unified metadata system, it supports cross-engine federal query engines to open up data for customers in the data center and realize converged computing and analysis of decentralized data in a cost-effective manner. Improve analytics efficiency by reducing unnecessary data transfers and ETL.
Business Pain Points
Data is scattered and stored on multiple storage media, and data from different media needs to be extracted and merged when data is produced.
There are grammatical differences in a variety of engines, which require different syntaxes for data processing, and the technical threshold for personnel is high.
Business Value
Based on unified engine technology and unified metadata system, it supports cross-engine federal query engines to open up data for customers in the data center and realize converged computing and analysis of decentralized data in a cost-effective manner. Improve analytics efficiency by reducing unnecessary data transfers and ETL.


WeChat Official Account

WeChat Tech Account

Douyin Account

WeChat Group Chat
WeChat Official Account
WeChat Tech Account
Douyin Account
WeChat Group Chat



