

 中文
中文Computing Platform


The unified resource pool management of multi-machine and multi-card supports the server to be automatically identified by the platform and quickly added to the resource pool through port authorization. No manual configuration is required. When the GPU needs to be maintained or replaced, the platform supports safe shelf removal and smooth migration.

A guarantee mechanism for resource allocation and task coordination to ensure that tasks can be executed efficiently and in an orderly manner in a multitasking environment. When the GPU is not fully utilized, it supports switching to an energy-saving state or reallocation, and real-time monitoring of resource usage, intelligent scheduling, and overload avoidance.

Through the computing power sharing mechanism, the fair allocation and efficient utilization of GPU resources are realized. The platform integrates a variety of GPU acceleration plug-ins, simplifies the application development and deployment process of users, and supports dynamically adjusting the allocation size of GPU resources according to actual needs to further improve resource utilization.
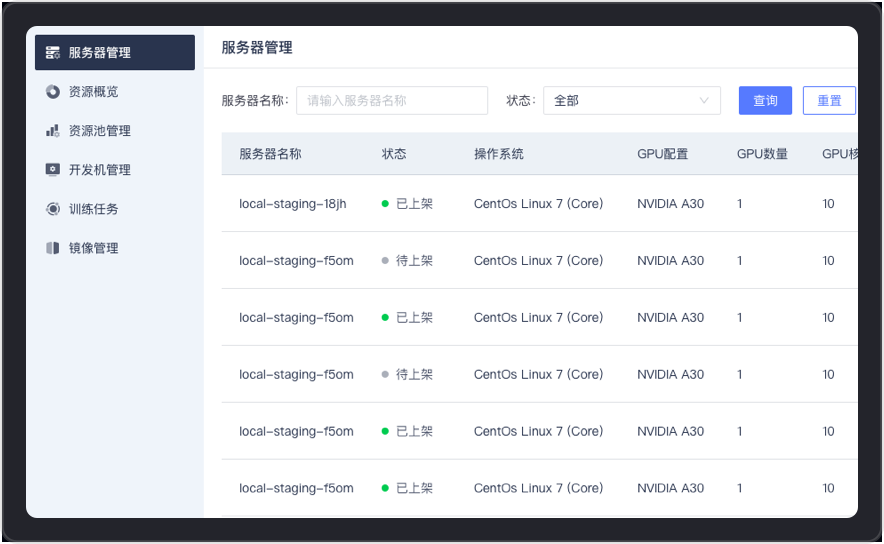
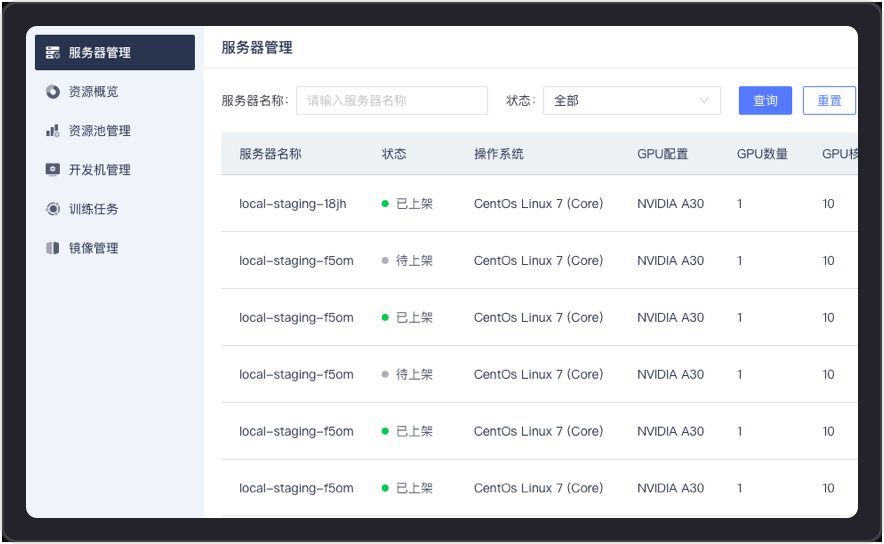
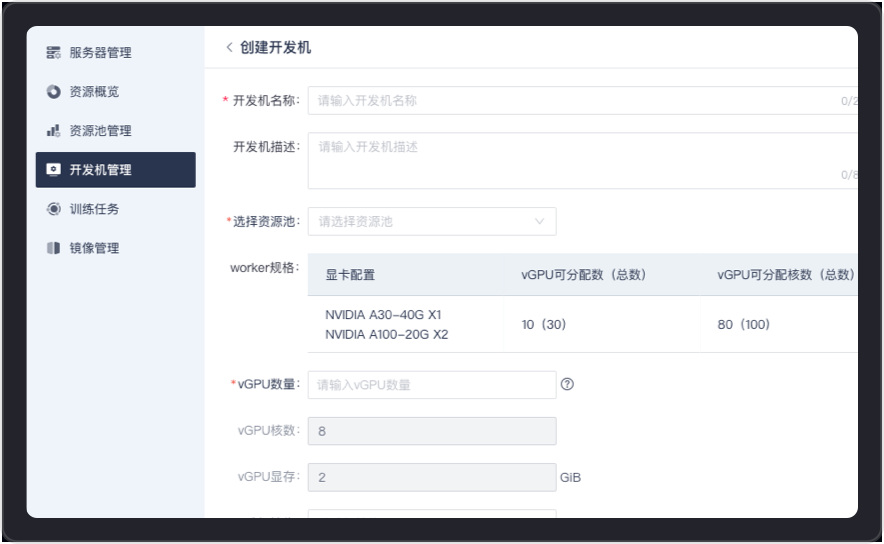
It supports full link process operations such as server creation, shelving, shelving, and GPU virtualization. Through port authorization, it can automatically identify and obtain complete information such as operating system, GPU number, GPU core number, and GPU memory, and conduct server connectivity testing and analysis to ensure flexible configuration and stable availability of resources.
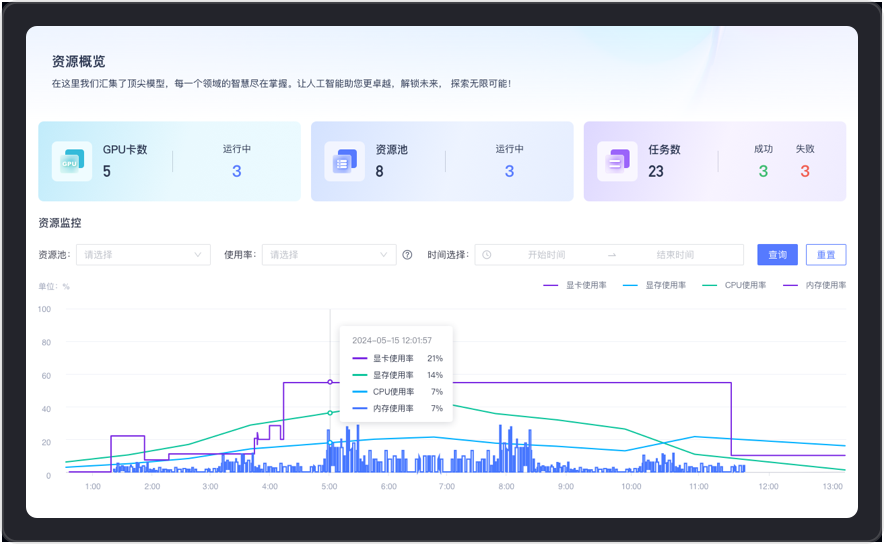
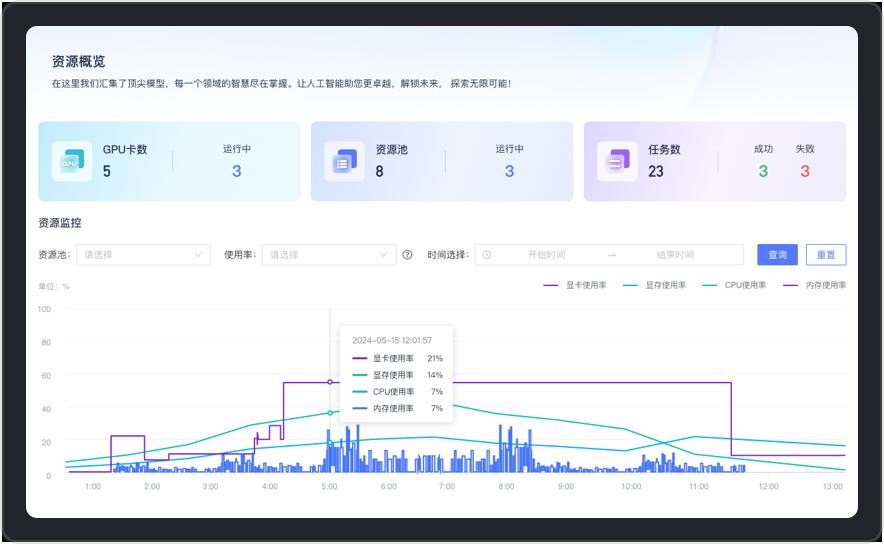
Comprehensive coverage of GPU card, resource pool and task-level performance and status monitoring, real-time tracking of resource pool usage, providing detailed data support for system health and performance optimization. Support GPU virtualization, multi-machine and multi-card parallel training to meet application-level computing power management.
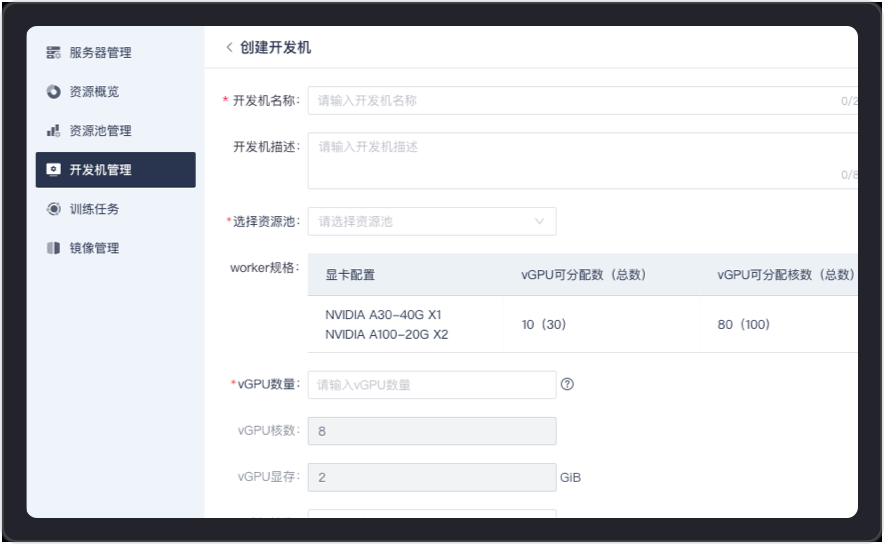
It provides users with a convenient developer creation and management environment. According to actual needs, the developer can be created by itself through the configuration of resource pool, vGPU number, image, and system disk size. At the same time, it provides high-performance storage space for each tenant to achieve tenant security isolation.
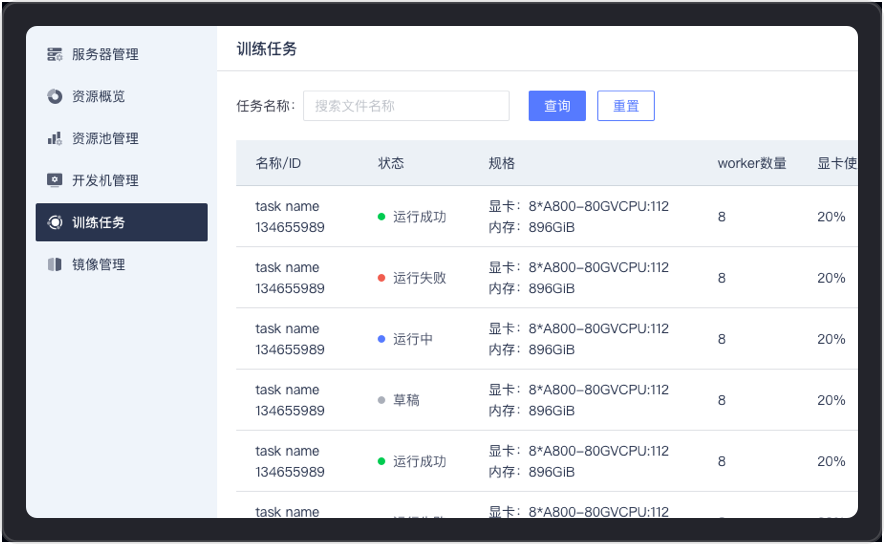
Support user-defined training parameters and configuration of training tasks, providing task anomaly detection, automatic restart of the process or rescheduling capabilities. The TensorBoard log function provides users with visualized training process monitoring and result analysis, further improving training efficiency and effectiveness.
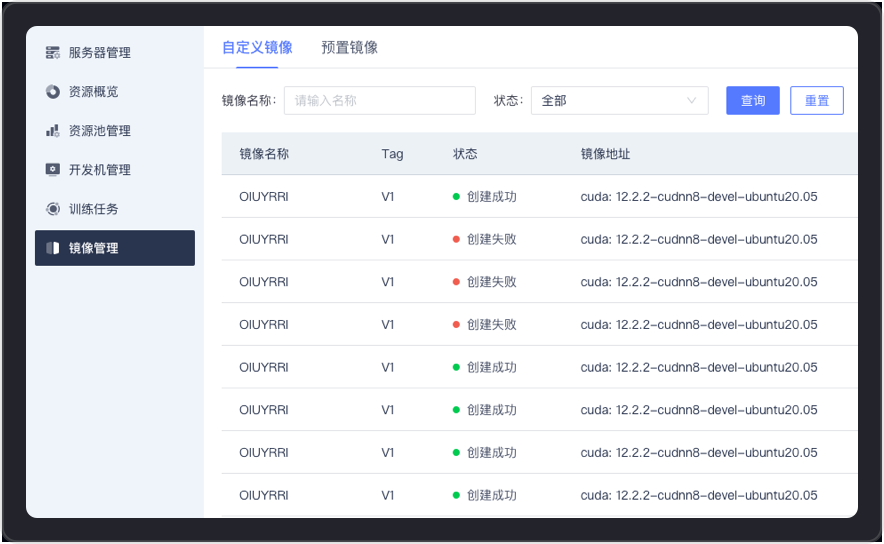
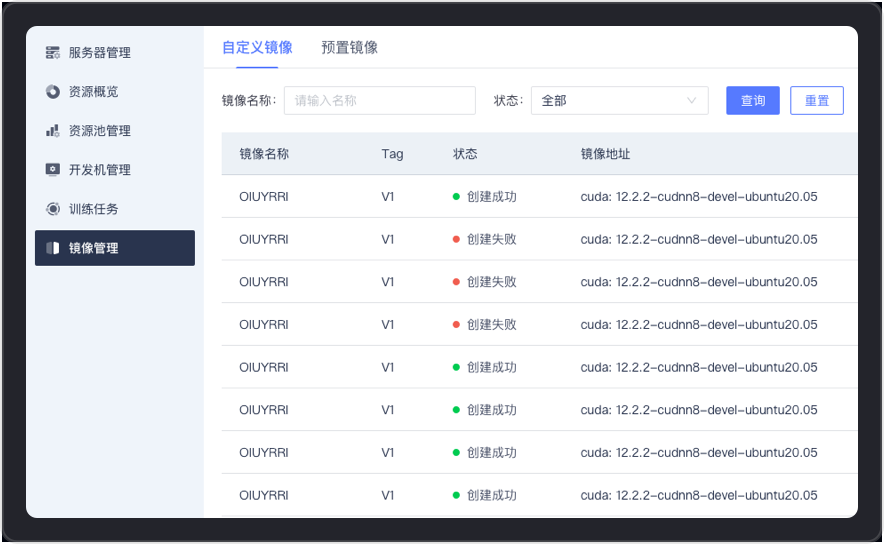
Supports the management and use of custom and pre-made images. Users can quickly create and deploy image environments. Services are applied to training tasks, development machines, Notebook modeling labs, etc., further meeting the diverse needs of AI model development and training process.
It supports full link process operations such as server creation, shelving, shelving, and GPU virtualization. Through port authorization, it can automatically identify and obtain complete information such as operating system, GPU number, GPU core number, and GPU memory, and conduct server connectivity testing and analysis to ensure flexible configuration and stable availability of resources.


Business Pain Points
Enterprise content data, algorithms, and service systems have not been effectively integrated independently, resulting in resource dispersion and difficulty in management and utilization. In addition, insufficient computing power centers and uneven distribution of deep learning resources cannot meet the needs of model training and real-time applications. Features, models and services are not unified, and MLOps machine learning development and operation and maintenance are inefficient, which brings great challenges to enterprises.
Business Value
Integration and efficiency: Integrate computing power resources and machine learning platforms to open up data development, feature management and model application to improve data efficiency and data consistency.
Resource scheduling: Optimize resource allocation, improve the efficiency of feature platform and model development, and support large-scale data processing and complex calculations.
Reduce costs and avoid risks: Improve data processing and model application capabilities, reduce human and technical costs, reduce the risk of data leakage and business interruption, and ensure long-term stability and reliability of operations.
Business Pain Points
Enterprise content data, algorithms, and service systems have not been effectively integrated independently, resulting in resource dispersion and difficulty in management and utilization. In addition, insufficient computing power centers and uneven distribution of deep learning resources cannot meet the needs of model training and real-time applications. Features, models and services are not unified, and MLOps machine learning development and operation and maintenance are inefficient, which brings great challenges to enterprises.
Business Value
Integration and efficiency: Integrate computing power resources and machine learning platforms to open up data development, feature management and model application to improve data efficiency and data consistency.
Resource scheduling: Optimize resource allocation, improve the efficiency of feature platform and model development, and support large-scale data processing and complex calculations.
Reduce costs and avoid risks: Improve data processing and model application capabilities, reduce human and technical costs, reduce the risk of data leakage and business interruption, and ensure long-term stability and reliability of operations.


WeChat Official Account

WeChat Tech Account

Douyin Account

WeChat Group Chat
WeChat Official Account
WeChat Tech Account
Douyin Account
WeChat Group Chat



